If you are a salesforce developer or architect planning to build a custom file import module in salesforce, this blog post would help you to identify key factors which you need to consider before you go about building the file import module using apex and visual force. If you have a legacy system where you have student data as an example and want to integrate with salesforce, this approach can be used as a semi Integration approach to solve the problem.
Validate the input file first before database operations
Once you identify the type of file which is going to be imported like a csv file or an xml file, you would want to map out the fields from the csv file to corresponding object in salesforce like account, contact or lead etc. The first thing you want to make sure is that you have validation built on the file import module which would look for column names on the csv file to match with prescribed column names and any change on the csv file with the order of the columns or extra columns should be caught as an exception and displayed to the user right away before you start loading data in salesforce.
The second prevalidation you would want to do is on data types of the csv file and throw exceptions if you have invalid data types on the csv file. E.g bad email fields, phone numbers, amount are typical example of fields where you want to display data validation errors.
Avoiding governor limits
In order to make the solution really scalable meaning to handle from 100 records in csv to 1 million records , you would want to use the apex batch to handle the post data handling for inserting or updating the data in salesforce. This is a major design consideration which you need to account for because most of the developers build all the data handling in an apex class which will hit the governor limit as soon as the volume of records become couple of thousands in the excel file. When you design an apex batch, here are certain key considerations which you want to consider.
1. Have a temporary object where you can store the data from CSV and then use the offset count on the batch to create as many batches leveraging salesforce batch count feature.
2. Make sure that there is a logging mechanism which would create one record for every batch run and create a child object for the master log object to handle every record inserted or updated. This would help in debugging of the log and help to pin point the exact child record which failed.
3. Create a rollback mechanism or transaction commit which would handle roll backs or commits on the database if there are any failures.
4. Create an email service which would send a status of the batch with the count of records inserted and updated. There should be an alert if the record counts in the csv does not match the record count of objects inserted or updated.
Handle debugging night mares
One of the challenges in building file imports is that the standard salesforce error debug mechanism will give you a general exception with generic line numbers which will not help you the developer or the user to fix the problem. You can log the exception but it does not help to identify the error record. To solve this, do the following steps.
1. On any exception, have a mechanism in place where you would log the error exception to the record which caused the problem . This can be done with Log master and Log details child object. The below screen shot shows the design of the Master log and Log details child object.
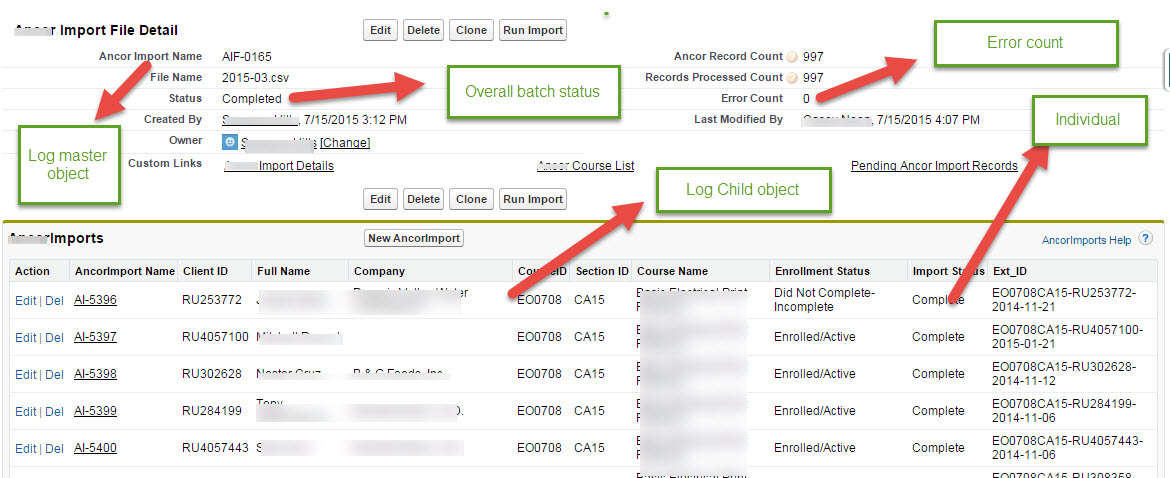
2. In a situation where you are unable to identify the source of the record which can happen using apex batch, creating a default status on the Log details would help to identify the range of records which cause the problem. For e.g once the record is processed by the batch, you would create the record in the Log details object with a status of new and once the record is inserted or updated, the status is changed to completed. If the batch fails for some reason, you can look at the Log details object child and show a report to the user with a status of new which would help the user to identify the range of records which caused the problem.
So here are the key takeaways which you should always consider for any file import module.
1. Always do preprocessing of the input file for column header mismatch and data types.
2. Use apex batch to process the input file and leverage batch count of salesforce which would help you to avoid governor limits.
3. Have logging of the master batch and child level record and report on success and failure of the records.
I hope this strategy would help to prevent major problems on building file import modules and help you to integrate your legacy systems with salesforce. Please feel free to email me at buyan@eigenx.com for further questions.
Please subscribe
Subscribe to our mailing list and get tips to maximize salesforce to your email inbox.
I am honored to have your subscription. Stay tuned for tips to maximize your salesforce investment
Something went wrong.




