If you are using Einstein Analytics, and you are in the process of loading millions of records into Einstein from an external database or warehouse with an ETL tool, this post would help you to follow the right strategy 🙂 . Einstein provides Analytics External Data API which could be used to load the data. Now if you have millions of records to be loaded, your option is to split the records into batches due to the 10mb limit and there are 2 governor limits which would happen as part of the data load. One is the CPU limit and concurrent API limit which happens due to the high volume of records. So How do you solve this problem? Unfortunately, there is not much documentation from the Einstein API for help. I would like to thank my friends Philippe Hamard from Chemours and Alam Mehboob from Wipro for contributing their knowledge on this.
Source of the problem.
When you use the Analytics External data API to load data from your external database, you have to use the following objects to load the data.
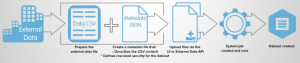
- InsightsExternalData
- InsightsExternalDataPart
- Patch
There is a great article on developer.salesforce.com which talks about the data load which you can check here. But the problem is that it does not have any documentation of the sequence of steps to load the data. So when you are loading say 3 million records and let us say you have 50 columns on your source file, you would be ending uploading 5000 records per chunk because 5000 records with 50 columns of data would exceed the 10 MB limit. So if your ETL tool no matter what tool you use would end up hitting the following governor limits.
- Max Concurrent Insights API Calls Per Org (Limit is 250).
- The maximum number of external data files that can be uploaded for each Wave Analytics dataset in a 24-hour rolling period (Limit is 50).
- CPU usage limit could reach 95%. This is an ETL tool specific issue and may not happen in all ETL tools.
The reason for the problem is that you would end up making around 500 calls to all the 3 Einstein APIs (for object InsightsExternalData, object InsightsExternalDataPart and Patch call which would hit the limits.
How do you solve this problem?
So here is the magic part of the problem. Instead of making 500 calls for each object individually, you should make 1 call to InsightsExternalData, 500 calls to InsightsExternalDataPart and 1 final Patch call. This is the actually the correct way to call this APIs but we missed it because it was not mentioned clearly in Salesforce documentation.
Here is the sequence to be followed:
- Create the 1st job by calling API for object insightexternaldata.
- Then start data upload to insightexternaldatapart object using Id from the job we just created above. This can be in a loop if you have 500 batches and you need to populate the object 500 times to populate the external data. This call would need to be done in a loop to populate all your data.
- Then 1 final Patch call to tell Salesforce that the job is ready for processing. So this would initiate processing on Einstein side to start loading the data in a dataset.
To summarize, here are things you need to be mindful when you are doing a heavy data load in Einstein.
- If you use the API, make sure your ETL tool or custom code calls the insightexternaldata call once, insightexternaldata part multiple times to populate data and the patch call to complete the transaction.
- Try to get an approximate size of your batch based on record count and column count so that it does not exceed 10 mb limit. Hopefully, Salesforce increases the limit!! 🙄
As always feel free to reach to post your comments or email me at buyan@eigenx.com for further questions.
Please subscribe
Subscribe to our mailing list and get tips to maximize salesforce to your email inbox.
I am honored to have your subscription. Stay tuned for tips to maximize your salesforce investment
Something went wrong.


Thanks for sharing this Buyan.
This will help Salesforce developers implementing the right approach to push million of data to Einstein using Wave Analytics APIs.
This will also help us in increasing the performance and reducing the time to load the data.
Description is nice and clear. Thanks a lot!!
Hi Mehboob,
Thanks again for your help and sharing your knowledge which helped me to create this post..
Buyan